Cumbria Spends : Database Import
Posted : Blog Post : 29.06.2020 - North West Open Data

1. Introduction
The next step I wanted to try was to pick a subset of councils and see how easy it was to download and compile into a region wide data set. From my previous post I realised automatic download was going to be a non-starter. So it was a quick trip around 6 Cumbrian Council websites downloading .CSV files covering January – December 2019. The files were downloaded into a council related sub directory for ease of processing. The councils covering Cumbria are
Carlisle City Council |
Allerdale Borough Council |
Eden District Council |
Copeland Borough Council |
South Lakeland District Council |
Barrow in Furnace Borough Council |
My initial aim was to load the files into staging tables of the same column order in a PostgreSQL database, resulting in six tables one for each council covering January – December 2019.
2. Methodology
I was using Cygwin on my laptop to run a PostgreSQL server, so had a UNIX environment available to me, so I wrote a short awk script to run on the CSV files, although awk isn’t CSV aware it’s good for processing tabular data. Here’s the output from running the script against one file.
Filename : Carlisle_City_Council_expenditure_exceeding_£250_August_2019.csv
Row 1 11 : Body ,Body Name ,Voucher No,Pay Date,Line Goods Amount,Name,Cred ID ,Cost ,Detail ,Line GL Code,Sercop
Row 2 11 : http://statistics.data.gov.uk/doc/statistical-geography/E07000028,Carlisle City Council ,ALE215430,07/08/2019,78.20,Adecco UK Ltd,71565,Street Cleaning,Agency Staff Pay,12150/0511,Street Cleansing
Max cols : 13
Min cols : 11
Tot recs : 547
Sus recs : 175
Filetype : ASCII textThis gave me an immediate ‘feel’ for the data in the file.
-
Filename – I could see how consistent the file naming standard was across the 12 files.
-
Row 1 – is usually the column descriptions of the data
-
Row 2 – is normally the first line of data
-
Max cols – the maximum number of columns found in all rows, awk would see a comma in a commented field as an extra column
-
Min cols – the minimum number of columns found in all rows
-
Tot recs – Total number of records, including header row
-
Sus recs – Number of records whose column count does not match the column count of the first row(the column description row)
-
Filetype – The output from the unix ‘file’ command
I then wrote a SQL file to create a table and ran it into the PostgreSQL server in a newly created ‘spends’ database.
create table carlisle_spend_2019(
Body character varying,
Body_Name character varying,
Voucher_No character varying,
Pay_Date date ,
Line_Goods_Amount character varying,
Name character varying,
Supplier_ID character varying,
Expense_Area character varying,
Expense_Type character varying,
Expense_Code character varying,
SeRCOP character varying
);I was importing everything in as a ‘character varying’ or varchar data type except for date, taking this approach gave me the added benefit of validating all date values on the import, this worked out quite well as it picked up date problems from one council. I would then load the data in using the ‘COPY’ command.
COPY carlisle_spend_2019(
Body ,
Body_Name ,
Voucher_No ,
Pay_Date ,
Line_Goods_Amount ,
Name ,
Supplier_ID ,
Expense_Area ,
Expense_Type ,
Expense_Code ,
SeRCOP )
FROM '/home/path/to/file/Carlisle_City_Council_expenditure_exceeding_£250_April_2019.csv' DELIMITER ',' CSV HEADER;Across the Cumbrian councils this would give me circa 27,000 rows of data for the year Individual councils rows varied from 1490 rows for Eden and 8364 for Carlisle. Copeland actually reported 1484 but April and May 2019 files were missing from the site. I contacted the Copeland via email and they turned the enquiry about the files into a FOI request so maybe at some point the files will turn up.
3. Issues Log
3.1. Windows New Line Format
Most of the files came withe a carriage return, line feed(CRLF) as the line terminators, this would show up in the Filetype value from the awk script, I would run the unix utility ‘dos2unix‘ on the files to get them into a cleaner unix format.
$ file local-transparency-report_september_2019.csv (1)
local-transparency-report_september_2019.csv: ASCII text, with CRLF line terminators
$ dos2unix local-transparency-report_september_2019.csv (2)
dos2unix: converting file local-transparency-report_september_2019.csv to Unix format...
$ file local-transparency-report_september_2019.csv (3)
local-transparency-report_september_2019.csv: ASCII text| 1 | Use 'file' to determine line terminators |
| 2 | Use dos2unix to convert to unix format |
| 3 | Checking the terminator after conversion |
3.2. Character Set Issues
These problems would manifest generally in the loading into PostgreSQL, the database had been created with a UTF8 character set. The load would fail with
ERROR: invalid byte sequence for encoding "UTF8"If you then viewed the file in ‘https://man7.org/linux/man-pages/man1/vi.1p.html[vi]’ you could see the offending characters appearing garbled or appearing as random numbers enclosed in ‘<‘ and ‘>’, for example “Software <96> maintenance” . Any file that failed I would run the unix ‘https://linux.die.net/man/1/iconv[iconv]‘ utility on the file to convert it to UTF8.
$ file *.csva (1)
payments-to-suppliers-over-250-february-2019.csv: Non-ISO extended-ASCII text, with very long lines
iconv -f CP1252 -t UTF8 payments-to-suppliers-over-250-february-2019.csv > lgtc_expenditure_2019_feb.csv
(2)
$ file *.csv (3)
lgtc_expenditure_2019_feb.csv: UTF-8 Unicode text, with very long lines| 1 | Using file to display character set |
| 2 | Using iconv to convert a file and redirect to new lgtc_expenditure_2019_feb.csv file |
| 3 | Displaying the new file’s encoding |
Character set issues arise when you consider how these files are generated, typically they may be extracted from a council database which has it’s own character set, then they may be mailed to employees to check and redact personal information. They will likely be loaded into spreadsheets and saved and mailed on before eventually being loaded onto a webserver, each client saving will potentially write the file to it’s default format. Here’s an indication of some of the character sets encountered.
$ file */*.csv | awk -F: '{print $2}' | sed -e 's/^[ \t]*//' | sort -u
Algol 68 source, Non-ISO extended-ASCII text
Algol 68 source, UTF-8 Unicode text
ASCII text
ISO-8859 text, with very long lines
Non-ISO extended-ASCII text
Non-ISO extended-ASCII text, with very long lines
UTF-8 Unicode text
UTF-8 Unicode text, with very long lines
UTF-8 Unicode text, with very long lines, with CRLF line terminators3.3. Money Format
For instance Carlisle Council reported money like this “£3,066.40” and Barrow used this style “1,234.00” . I removed the pound symbol with ‘vi‘ the unix text editor and got rid of the commas after loading into PostgeSQL as follows
update carlisle_spend_2019
set line_goods_amount=REPLACE(line_goods_amount,',','');3.4. Empty Fields/Extra Rows
Allerdale Council produced files with alot of empty fields per line, each line had 20 odd commas at the end, representing empty cells in the spreadsheet presumably. These were removed with search and replace in ‘vi‘
Name,Sub Group,Service Areas,Expense Type,Narrative,Date,Transaction Number,Amount,Supplier Name,Supplier Ref,Period,Year,,,,,,,,,,,,,,,,,,,,,,Carlyle Council’s March file had 522 empty rows, I removed these in the database.
One council had a Row 1 as a header line describing the data set and Row 2 describing the columns and Row 3 as the first row of data, I just removed Row 1.
3.5. Incorrect Columns
South Lakes produced a problem with one of it’s files, if we examine the Min cols value from the check script
$ ../scripts/check_csv.sh *payments*.csv | grep Min
Min cols : 15
Min cols : 15
Min cols : 15
Min cols : 17 (1)
Min cols : 15
Min cols : 15
Min cols : 15
Min cols : 15
Min cols : 15
Min cols : 15
Min cols : 15
Min cols : 15| 1 | One file has 17 columns |
The payments-to-suppliers-over-250-february-2019.csv file had an extra 2 columns. I compared Row 1 between the February and the March CSV files.
1 OrganisationNameLabel,
2 OrganisationURI,
3 EffectiveDate,
4 Directorate/ServiceWhereExpenditureIncurred,
5 ServiceCategoryLabel,
6 ServiceCategoryURI,
7 Supplier,
8 SupplierRegisteredCompany Number,
9 PaymentDate,
10 TransactionNumber,
11 NetAmount,
12 IrrecoverableVAT,
13 PurposeOfSpend,
14 PurposeOfSpend, (1)
15 Procurement (Me, (2)
16 ProcurementClassification:ProclassLabel,
17 ProcrementClassification:ProClassCode| 1 | duplicate column |
| 2 | extra column |
1 OrganisationNameLabel,
2 OrganisationURI,
3 EffectiveDate,
4 Directorate/ServiceWhereExpenditureIncurred,
5 ServiceCategoryLabel,
6 ServiceCategoryURI,
7 Supplier,
8 SupplierRegisteredCompany Number,
9 PaymentDate,
10 TransactionNumber,
11 NetAmount,
12 IrrecoverableVAT,
13 PurposeOfSpend,
14 ProcurementClassification:ProclassLabel,
15 ProcrementClassification:ProClassCodeI loaded the file into a Google Sheet and deleted the two extra columns, saved it and loaded it into the database.
3.6. Incorrect Dates
Eden Council seemed to have a persistent problem with some date values, they generally manifested themselves at the end of the files and covered Bank Service Charges, however there were extensive problems with the November 2019 CSV file. Here’s the last 2 lines of the February file
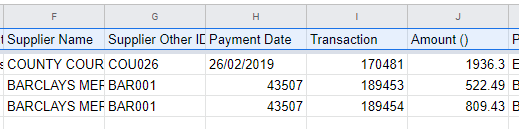
I’m going to contact Eden Council but in the interests proving this approach and still retain some visibility of the issue I decided to alter all such values to the 28th of the month in which they occurred. Some measure of the number of rows this affected can be seen from the following query in the database that shows number of records per day of month.
spends=# select date_part('day',payment_date),count(*)
from eden_spend_2019
group by date_part('day',payment_date)
order by date_part('day',payment_date);
date_part | count
-----------+-------
1 | 50
2 | 2
3 | 31
4 | 8
5 | 17
6 | 70
7 | 24
8 | 70
9 | 28
10 | 54
11 | 36
12 | 70
13 | 70
14 | 28
15 | 68
16 | 43
17 | 34
18 | 62
19 | 10
20 | 79
21 | 40
22 | 61
23 | 41
24 | 21
25 | 32
26 | 38
27 | 35
28 | 224 (1)
29 | 64
30 | 52
31 | 28
(31 rows)| 1 | Distorted distribution of 28th count |
4. Conclusions & Next Steps
Actually this proved to be a little easier than I expected, there were no real show stoppers. All councils produced monthly files, it is still frustrating that the landing page, file name and access to full urls in the page highlighted in the last post still means a scripted download is still problematic.
The main issue is with the missing date information highlighted in the Eden data and the two missing files from Copeland. Hopefully these can be resolved.
I currently have six tables in the database comprising of one years spend data for 2019. I’m fairly confident that the date information is validated on their import to a date data type specified column in the table. I’m thinking over some options for the next steps
-
Are there any other sources of spend data that are missing eg. Government Procurement card, credit card spends etc
-
There are between 7 and 15 columns of data made available from the councils, there are 6 mandated fields and 1 required field defined in the LGA Spending and Procurement Validator page.
-
Aggregating the diverse data sets and definition of the target council wide spending table
-
Any other tables I might need to define for the schema
-
I’ll convert and validate the spend amount from a varchar to a numeric value when I populate the main table
-
Review the spending categories used by these 6 councils and see if they relate in anyway
-
Is there information I can extract for future use, eg Sercop codes and category definitions, etc.
-
Are there ways of enriching the data set, eg. external company information
-
Check out Cumbria Council, and understand the relationship of spends between the regional council and the local councils covered here.