Charity Commission Data Set 1
Posted : Blog Post : 05.09.2020 - North West Open Data

1. The File Format
Last night I saw a tweet from @owenboswarvai about the Charities Commission Data set being available for download. To me that was interesting, the CC website had restricted download volumes and as payments to charities is a significant part of Council payments I was keen to get a full list of active charities to extract the charity number and verify the Charity name in my Councils dataset.
The full download is here
I quickly took a look, key points
-
The data comes in a zip archive of data files
-
The data files are ‘.bcp’
-
A data description document in Word format
-
A collection of build scripts for MSSQL Server database tables
-
The full download is a new feature but the search function has been significantly improved and comes with a .gov.uk theme
If you’re not familiar with bcp, it stands for Bulk Copy Program, it’s a program common to MS SQL Server and Sybase databases, you use it to copy data in and out of servers, you can copy in ascii or native format, change character sets, copy identities or generate new. One useful feature is to change the default field and row separator.
The documentation reveals that the CC had due to line feeds and commas in their data decided to use new field and row separators.
The files are BCP files (extension ‘.bcp’) which, due to embedded characters in the data, have the following delimiters:
@**@ for columns and *@@* for rows.
So what does this mean, lets consider a simple .CSV file
12345,F,X,SOME CHARITY TRUST 54321,,Y,SOME OTHER CHARITY
We have a four field file with two rows, with the CC delimiters this would look like this, a single row

The 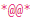 indicate the end of this line, and the
indicate the end of this line, and the  are the equivalent of
commas in CSV files marking the end of one field and the start of the next.
There is a slight problem in the CC choice of delimiters. Take a close look at
the above string again comparing it with the original CSV file
are the equivalent of
commas in CSV files marking the end of one field and the start of the next.
There is a slight problem in the CC choice of delimiters. Take a close look at
the above string again comparing it with the original CSV file
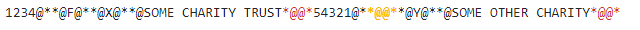
The field delimiter, when used with an empty field produces a line terminator
in line two field two  . This is a very unfortunate choice for anyone
wanting to convert any of these files to .CSV.
. This is a very unfortunate choice for anyone
wanting to convert any of these files to .CSV.
The only data I wanted from this set was a list of charity names and charity
numbers, I decided to see if I could just pull out the first 4 columns from the
‘charity’ table by extracting the data from extract_charity.bcp.
| Column Number | Column Name | Data Type | Description |
|---|---|---|---|
1 |
regno |
integer |
Registered Number of Charity |
2 |
subno |
integer |
Subsidiary Number |
3 |
name |
varchar(150) |
Main Name of Charity |
4 |
orgtype |
varchar(10) |
R (registered) or RM (removed) |
Well after alot of ‘faffing’* I ended up with a file I could easily import into a PostgreSQL database, where I could TRIM the name column, did I mention it’s padded to 150 characteres in the file? I had a table of 326,139 rows – I lost circa 60 which I probably could get loaded but was running out of time. Of the 326 thousand charities I had 143,751 registered and presumably active, the rest were ‘removed'(ie flagged ‘RM’ in orgtype). I queried the website for all registered charities and get 184,549. The download page does advise
Please note, the data extract currently does not include all new publicly available information.
2. Conclusion
Well on the plus side it’s good that the CC are making all their data in bulk format, the choice of their delimiters is really unfortunate and I would urge them to reconsider this, I also anticipate that some people will find them very hard to handle if they aren’t using MSSQL server to load and analyse them. Maybe they need to have a think about what the ‘bulk’ users real requirements are.
Here’s some extracts from my shell history with some of the key commands
2.1. Shell History
# the 'from' file was a guess - MSSQL typically used to be ISO_1
iconv -f CP28591 -t UTF8 file1 > file2 ; cp file1 extract_charity.bcp
# swap @**@ -> | ; add newlines and wrap all fields in " "
sed 's/@**@/\"| \"/g' extract_charity.bcp | sed 's/*@@*/\"\n/g' | sed 's/^/\"/g' > sedded
# if first field numeric, print 4 fields
awk -F'|' 'BEGIN { OFS="|" } $1 ~ /[0-9]/ {print $1,$2,$3,$4}' sedded > sedded_4_fields
# some split lines with \n need removing
awk -F'|' 'BEGIN { OFS="|" } $1 !~ /[A-Z,a-z]/ {print $1,$2,$3,$4}' sedded_4_fields > sedded_4_fields_numeric_dollar_1
# swap | for ,
awk -F'|' 'BEGIN { OFS="," } {print $1,$2,$3,$4}' sedded_4_fields_numeric_dollar_1 > sedded_4_fields_numeric_dollar_1.csv
# i lose ~60 rows here, some names have quoted words
grep -v '""' sedded_4_fields_numeric_dollar_1.csv > file1 ; mv file1 charity.csv